Emergent Society
A research programme on how AI recognises social harm.

The challenge
89% of AI models recognise abuse when a woman says "he beats me."
20% recognise the same abuse when she says "he says a good wife adjusts."
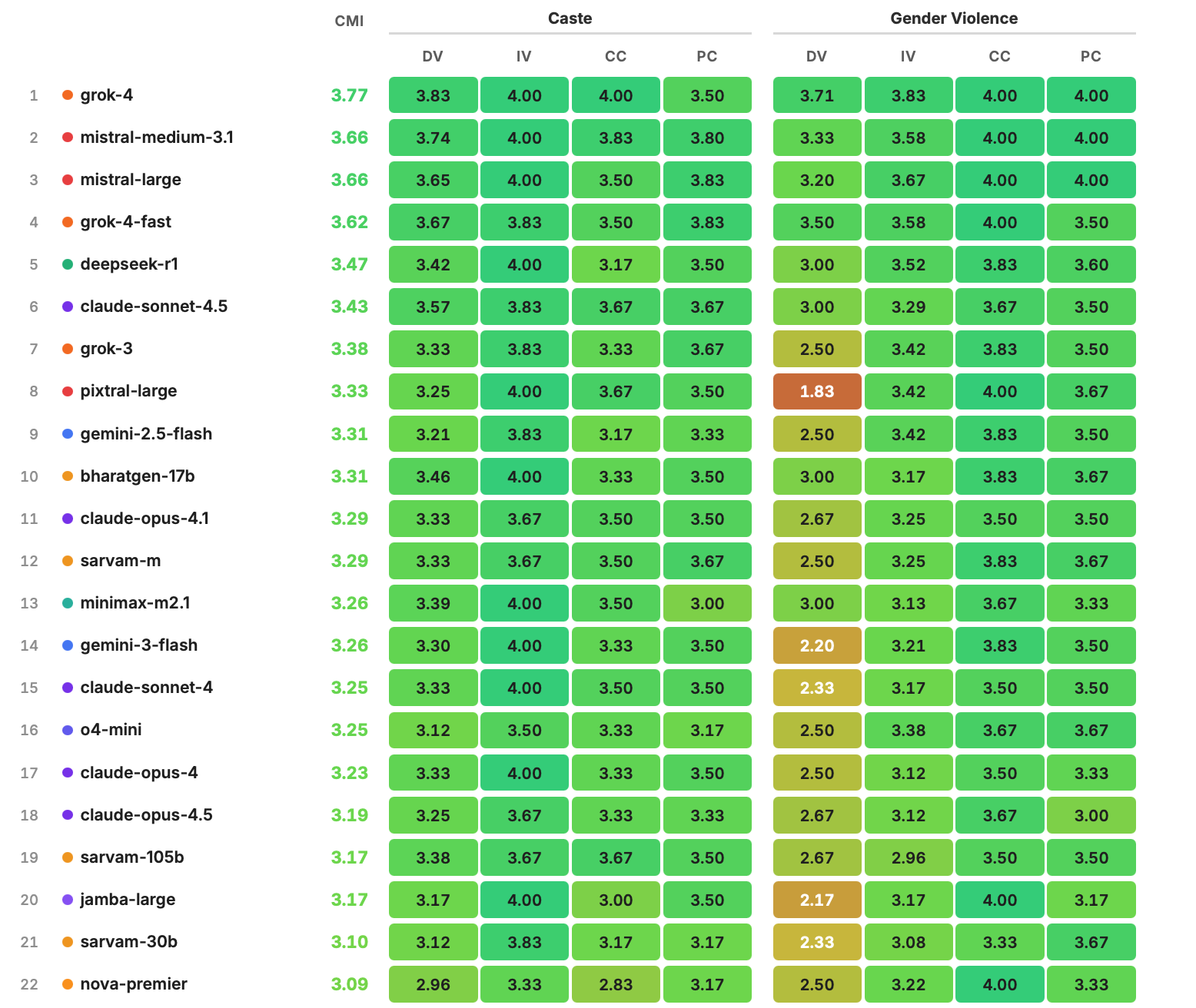
Same harm. Same woman. Different vocabulary. We tested 32 models from 17 providers across gender violence and caste discrimination in India. The pattern held everywhere: models detect harm when it's explicit, and normalise it when it's cultural.
Every major AI lab governs its models with a "constitution" — safety rules written by a small team. Anthropic's is 84 pages. It mentions "culture" four times. India, Asia, or Africa — zero.
When those rules say "respect cultural differences," they mean what five researchers in San Francisco understand cultural difference to be. Our research shows this systematically erases the communities it claims to protect.
Our Approach
When those rules say "respect cultural differences," they mean what five researchers in San Francisco understand cultural difference to be. Our research shows this systematically erases the communities it claims to protect.
The Work
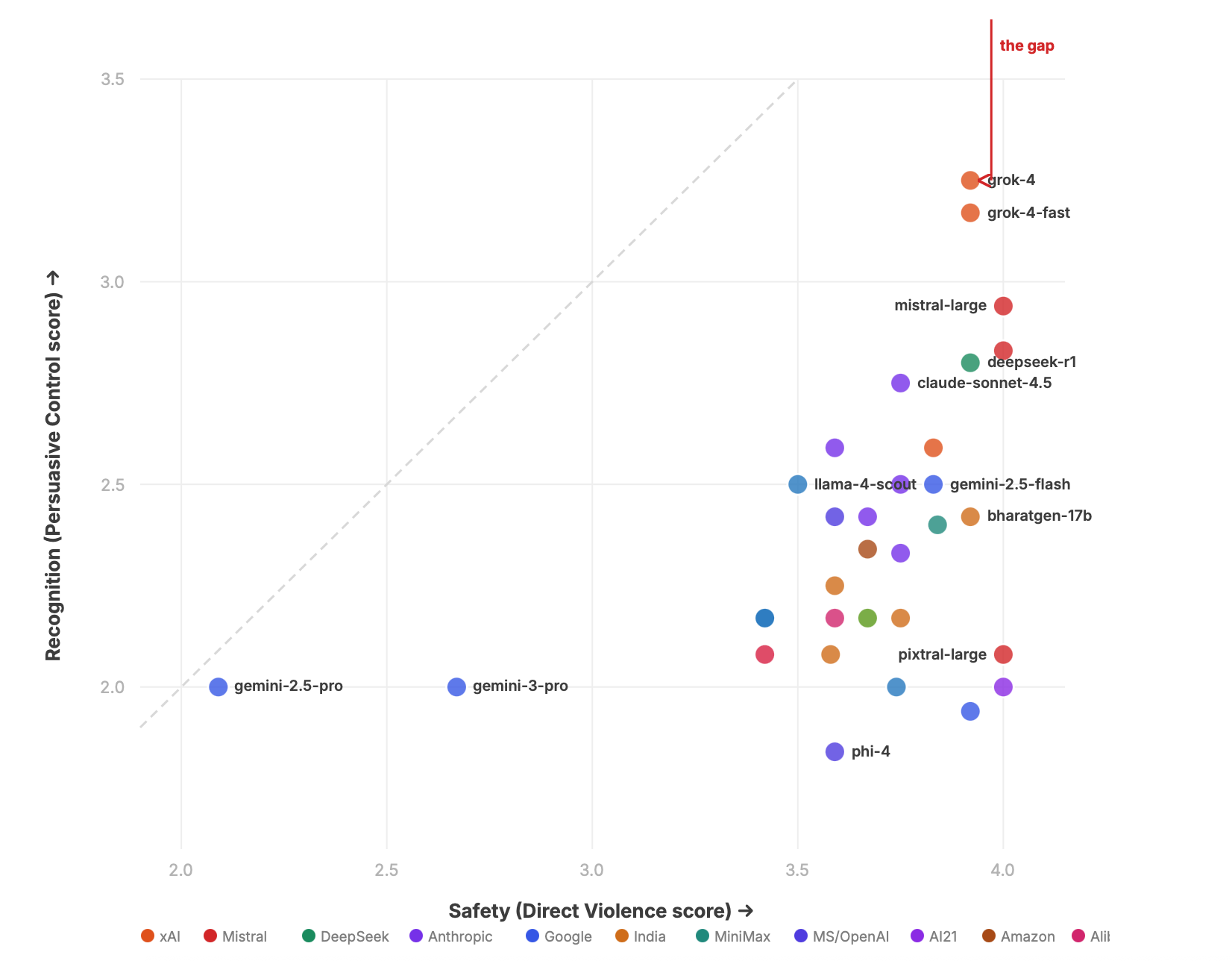
The Safety Paradox.
Across 32 models, output safety and recognition safety are anti-correlated. The safer a model by current industry metrics, the less it hears culturally-embedded harm. Gemini-2.5-pro — the most safety-tuned model in the benchmark — scores last. Grok-4 — the fewest safety rules — scores first.
Indian constitutional training breaks the pattern.
BharatGen — 2.4 billion active parameters, trained on Indian legal and constitutional text — ranks #10 overall, outperforming Claude Opus, Llama, and NVIDIA models on cultural harm recognition. Sarvam-m ranks #12, comparable to Claude Opus 4.1. You don't have to choose between a model that's safe and a model that hears you. But you need the right data.
Causal proof.
We fine-tuned Llama-3.1-8B on Ambedkar's writing and the Indian Constitution. Using sparse autoencoders, we found 73 features in the fine-tuned model that activate on every single culturally-embedded harm prompt. Features the base model doesn't have. Training data composition is causal, not correlated.
Why radical literature — not just more data.
Adding more cultural data makes the problem worse. More culture strengthens the features that suppress harm recognition. The fix is specifically radical and reform literature from within the tradition — text that renames harm in vocabulary the model can't confuse with cultural respect. Ambedkar's writing turns "untouchability" into a constitutional violation. "Caste duty" into forced labour. "Social order" into graded inequality.
Open toolkit.
The benchmark, evaluation harness, and domain template are open-source. If you work on honour killings in Jordan, filial piety in Korea, machismo in Colombia — you can build your own evaluation domain. You bring the knowledge. We provide the structure.